

So installieren und konfigurieren Sie Hive mit hoher Verfügbarkeit - Teil 7

- 4059
- 683
- Levke Harnapp
Bienenstock ist ein Data Warehouse Modell in Hadoop Ökosystem. Es kann als ETL -Tool darüber hinaus ausgeführt werden Hadoop. Aktivierung der hohen Verfügbarkeit (HA) für Hive ist nicht ähnlich wie in Master -Diensten wie Namenode und Resource Manager.
Automatisches Failover erfolgt nicht in Bienenstock (Hiveserver2). Wenn überhaupt Hiveserver2 (HS2) fehl HS2 wird scheitern. Wir müssen den Job erneut einsetzen, damit der Job auf anderen ausgeführt werden kann Hiveserver2. Also aktivieren HA An HS2 ist nichts anderes, aber erhöht die Zahl von HS2 Komponenten in Cluster.
In diesem Artikel sehen wir die Schritte zur Installation und Aktivierung des Hohe Verfügbarkeit von Bienenstock.
Anforderungen
- Best Practices für die Bereitstellung des Hadoop -Servers auf CentOS/RHEL 7 - Teil 1
- Einrichten von Hadoop -Voraussetzungen und Sicherheitshärten - Teil 2
- So installieren und konfigurieren Sie den Cloudera -Manager auf CentOS/RHEL 7 - Teil 3
- So installieren Sie CDH und konfigurieren Sie Serviceplatzierungen auf CentOS/RHEL 7 - Teil 4
- So richten Sie eine hohe Verfügbarkeit für Namenode - Teil 5 ein
- So richten Sie eine hohe Verfügbarkeit für Ressourcenmanager ein - Teil 6
Lass uns anfangen…
Bienenstockinstallation und Konfiguration
1. Einloggen in Cloudera Manager am folgenden URL und navigieren Sie zu Cloudera Manager -> Service hinzufügen.
http: // 13.233.129.39: 7180/cmf/home
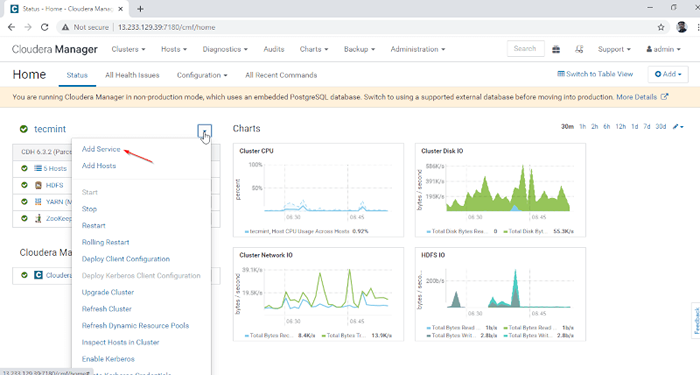 Fügen Sie Service in Cloudera Manager hinzu
Fügen Sie Service in Cloudera Manager hinzu 2. Wählen Sie den Service 'Bienenstock''.
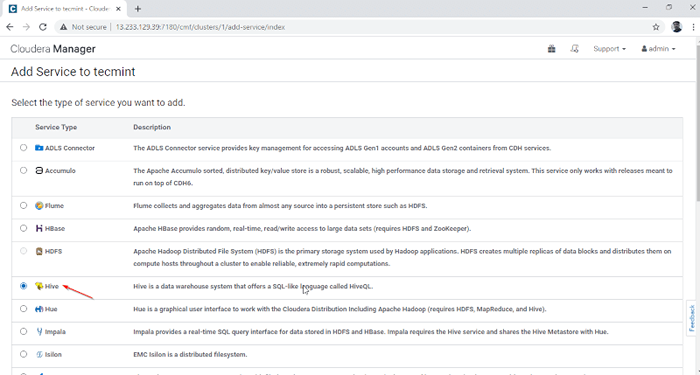 Wählen Sie den Hive -Service
Wählen Sie den Hive -Service 3. Weisen Sie die Dienste auf Knoten zu.
- Tor - Es ist der Client -Dienst, in dem der Benutzer auf den Bienenstock zugreifen kann. Normalerweise wird dieser Service in platziert Rand Knoten, die den Benutzern gewidmet sind.
- Hive Metastore - Es ist ein zentrales Repository für die Aufbewahrung von Hive -Metadaten.
- WebHCAT -Server - Es ist eine Web -API für Hcatalog und andere Hadoop -Dienste.
- Hiveserver2 - Es ist eine Schnittstelle von Clients für die Ausführung von Abfragen auf Hive.
Nachdem die Server ausgewählt wurden, klicken Sie auf 'Weitermachen' fortfahren.
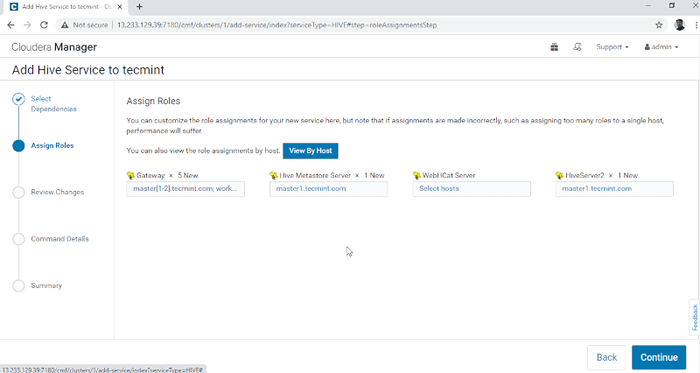 Weisen Sie Dienst als Knoten zu
Weisen Sie Dienst als Knoten zu 4. Hive Metastore benötigt eine zugrunde liegende Datenbank zum Speichern von Metadaten. Hier verwenden wir die Standardeinstellung PostgreSQL Datenbank, die mit eingebaut wird mit CDH.
Nachfolgend werden die genannten Datenbankdetails automatisch eingegeben. 'Testverbindung'wird übersprungen, da die genannte Datenbank im laufenden Fliegen erstellt wird. In Echtzeit müssen wir die Datenbank in der externen Datenbank erstellen und die Verbindung testen, um weiter fortzufahren. Sobald er fertig ist, klicken Sie bitte auf 'Weitermachen''.
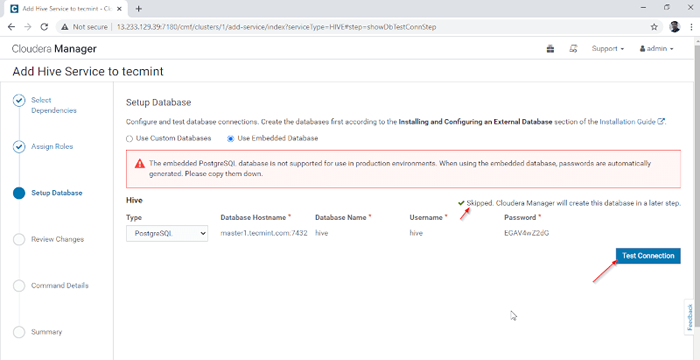 Setup -Datenbank
Setup -Datenbank 5. Konfigurieren Sie die Hive -Lagerhaus Verzeichnis, /Benutzer/Hive/Lagerhaus ist der Standardverzeichnispfad zum Speichern von Hive -Tischen. Drücke den 'Weitermachen''.
 Wählen Sie Hive Warehouse Directory
Wählen Sie Hive Warehouse Directory 6. Die Installation von Hive wird gestartet.
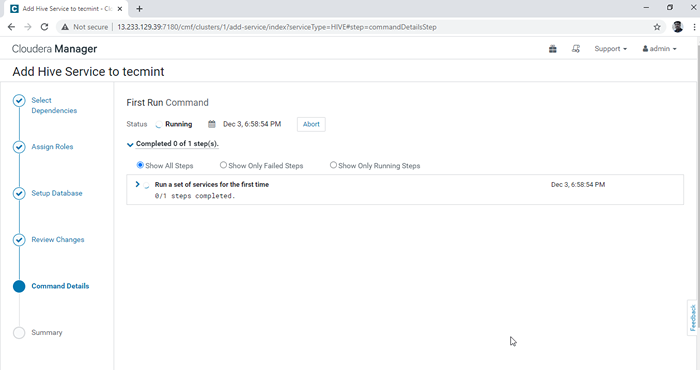 Bienenstock -Installationsfortschritt
Bienenstock -Installationsfortschritt 7. Nach Abschluss der Installation können Sie die 'erhalten'Fertig'Status. Klicken 'Weitermachenweiter vorgehen.
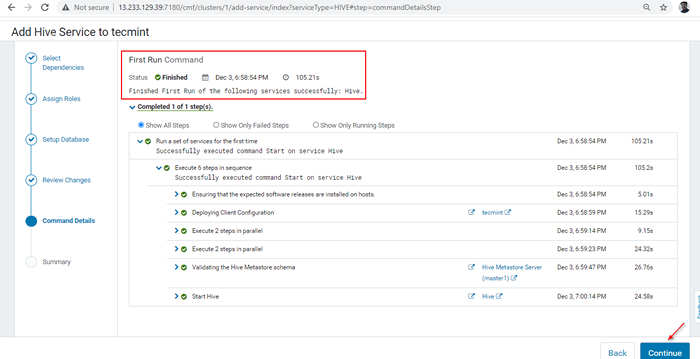 Bienenstockinstallation abgeschlossen
Bienenstockinstallation abgeschlossen 8. Die Installation und Konfiguration von Bienenstöbern erfolgreich abgeschlossen. Klicken 'Beenden'Um den Installationsverfahren abzuschließen.
 Beenden Sie die Bienenstockinstallation
Beenden Sie die Bienenstockinstallation 9. Du kannst das ... sehen Bienenstock Service hinzugefügt Cluster durch Cloudera Manager Dashboard.
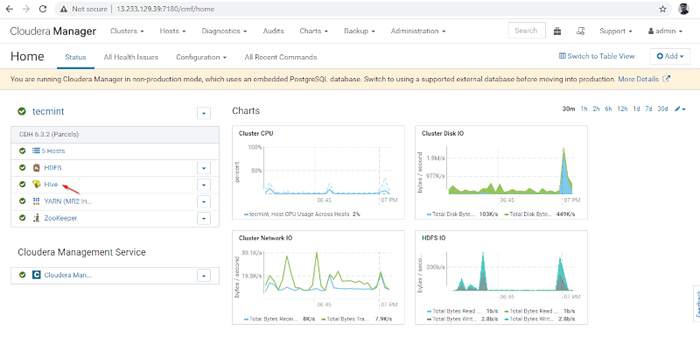 Hive -Service hinzugefügt
Hive -Service hinzugefügt 10. Sie können die anzeigen Hiveserver2 In Instanzen von Bienenstock. Wir haben hinzugefügt Hiveserver2 In Master1.
Cloudera Manager -> Bienenstock -> Instanzen -> Hiveserver2.
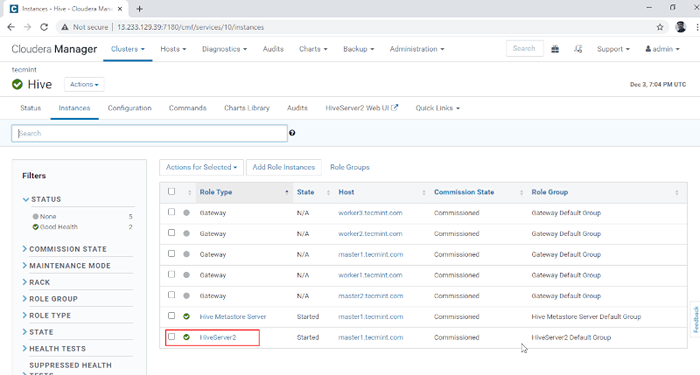 Sehen Sie sich HiveServer2 -Instanzen an
Sehen Sie sich HiveServer2 -Instanzen an Ermöglichen Sie eine hohe Verfügbarkeit von Bienenstock
11. Nächst Cloudera Manager -> Bienenstock -> Aktionen -> Rolle hinzufügen Instanzen.
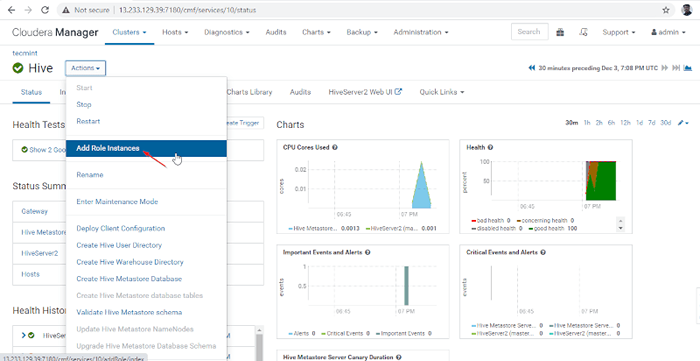 Fügen Sie Bive Rolleninstanz hinzu
Fügen Sie Bive Rolleninstanz hinzu 12. Wählen Sie die Server aus, auf denen Sie extra platzieren möchten Hiveserver2. Sie können mehr als zwei hinzufügen, es gibt keine Begrenzung. Hier fügen wir zusätzliche hinzu Hiveserver2 In Master2.
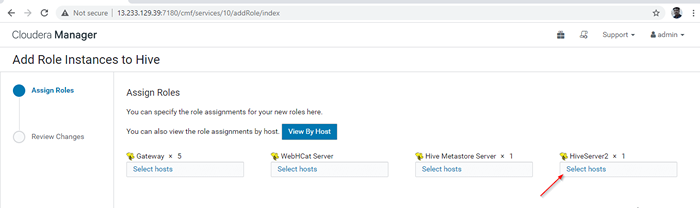 Wählen Sie Server für Hive
Wählen Sie Server für Hive 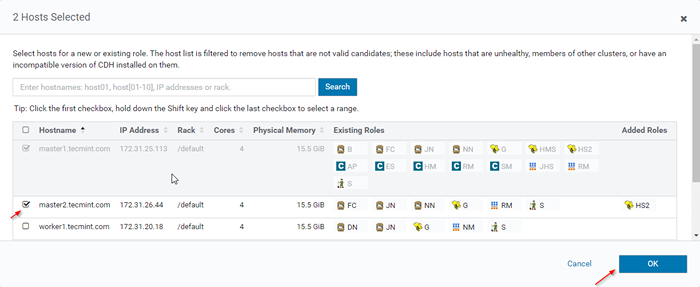 Wählen Sie Host Server
Wählen Sie Host Server 13. Klicken Sie nach der Auswahl des ServersWeitermachen''.
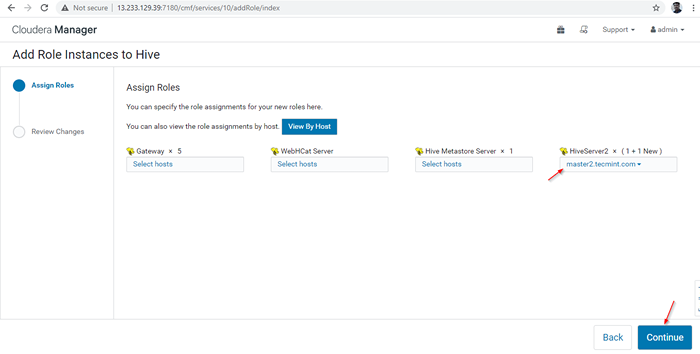 Server hinzugefügt
Server hinzugefügt 14. A Hiverserver2 wird in die hinzugefügt Bienenstockinstanzen, Sie müssen damit beginnen, indem Sie gehen Cloudera Manager -> Bienenstock -> Instanzen -> (Wählen Sie HiveServer2 neu hinzugefügt) -> Aktion für ausgewählte -> Start.
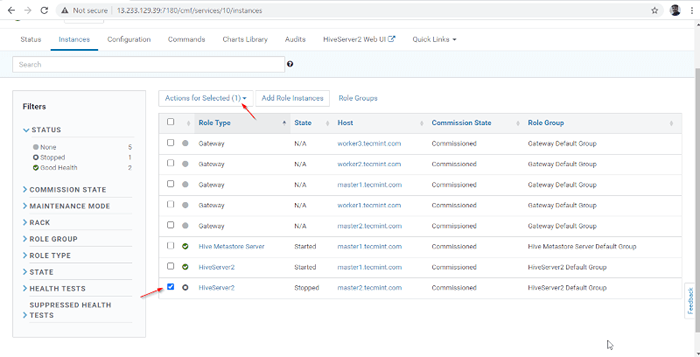 Wählen Sie Hive -Server
Wählen Sie Hive -Server 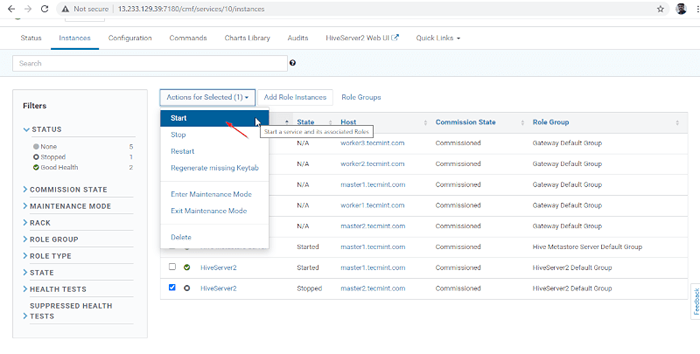 Starten Sie den Hive -Server
Starten Sie den Hive -Server 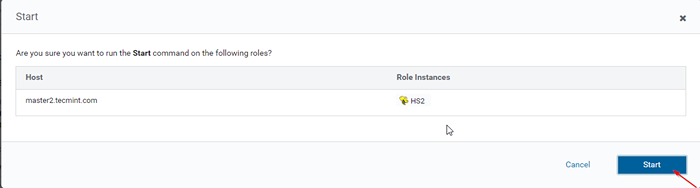 Starten Sie den Hive -Server
Starten Sie den Hive -Server 15. Einmal Hiveserver2 begann am Master2, Sie erhalten den Status 'Fertig''. Klicken Schließen.
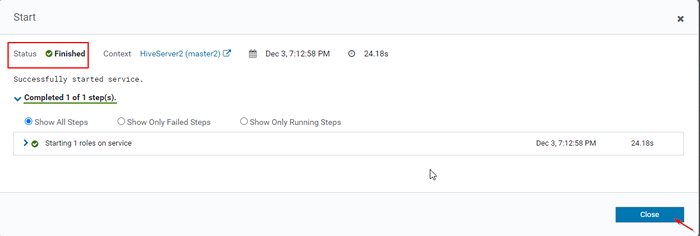 Status: Abgeschlossen
Status: Abgeschlossen 16. Sie können beide anzeigen, beide HIVERVER2S Rennen.
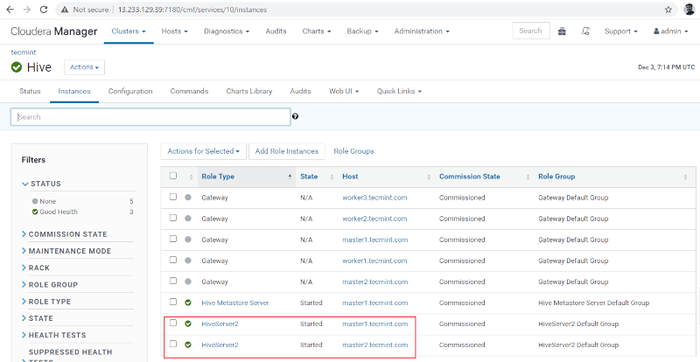 Überprüfen Sie den Status des Hive -Servers
Überprüfen Sie den Status des Hive -Servers Überprüfen Sie die Verfügbarkeit der Bienenstock
Wir können die verbinden Hiveserver2 Durch die Greine, die ein dünner Client und eine Befehlszeile ist. Es verwendet den JDBC -Treiber, um die Verbindung herzustellen.
17. Melden Sie sich beim Server an, wo Hive -Tor läuft.
[[E -Mail geschützt] ~] $ Beeline
 Verbindung zu Hiveserver2 herstellen
Verbindung zu Hiveserver2 herstellen 18. Geben Sie die JDBC Verbindungszeichenfolge, um die zu verbinden Hiveserver2. In diesem Zusammenhang die Saite Wir erwähnen die Hiverserver2 (Master2) mit seiner Standard -Portnummer 10000. Diese Verbindungszeichenfolge stellt nur eine Verbindung zu dem her Hiveserver2 das läuft weiter Master2.
Vorhöhe> !Verbinden Sie "JDBC: HIVE2: // Master1.Tecmint.com: 10000 "
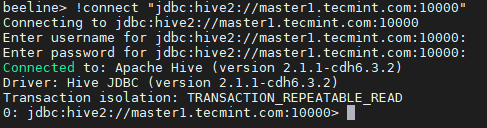 JDBC -Verbindungszeichenfolge
JDBC -Verbindungszeichenfolge 19. Führen Sie eine Beispielanfrage aus.
0: JDBC: HIVE2: // Master1.Tecmint.com: 10000> Datenbanken anzeigen;
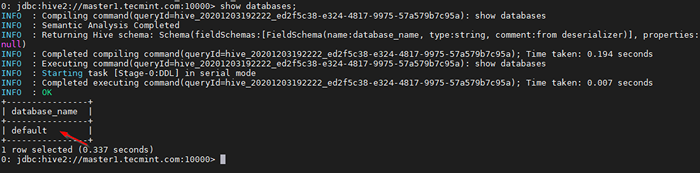 Probenabfrage ausführen
Probenabfrage ausführen Dies ist die Standarddatenbank, die integriert wird.
20. Verwenden Sie den folgenden Befehl, um die Hive -Sitzung zu beenden.
0: JDBC: HIVE2: // Master1.Tecmint.com: 10000> !aufhören
 Beenden Sie die Hive -Sitzung
Beenden Sie die Hive -Sitzung 21. Sie können die gleiche Weise verwenden, um eine Verbindung herzustellen Hiveserver2 Laufen Master2.
Vorhöhe> !Verbinden Sie "JDBC: HIVE2: // Master2.Tecmint.com: 10000 "
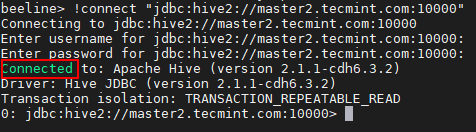 Stellen Sie eine Verbindung zum Hive -Server her
Stellen Sie eine Verbindung zum Hive -Server her 23. Wir können die verbinden Hiveserver2 In Zookeeper Entdeckung Modus. In dieser Methode müssen wir die nicht erwähnen Hiveserver2 In der Verbindungszeichenfolge verwenden wir stattdessen Zookeeper Um die verfügbaren zu entdecken Hiveserver2.
Hier können wir einen Lastausgleich von Drittanbietern verwenden, um die Ladung unter den verfügbaren Ausgleichen auszugleichen Hiverserver2. Die folgende Konfiguration muss aktiviert werden Zookeeper -Erkennungsmodus durch gehen zu Cloudera Manager -> Bienenstock -> Aufbau.
 Aktivieren Sie den Erkennungsmodus des Zookeeper
Aktivieren Sie den Erkennungsmodus des Zookeeper 24. Suchen Sie als nächstes die Eigenschaft “HiveServer2 Advanced Configuration SnippetUnd klicken Sie auf die + Symbol zum Hinzufügen der folgenden Eigenschaft.
Name: Bienenstock.Server2.Unterstützung.dynamisch.Service.Entdeckungswert: True Beschreibung:
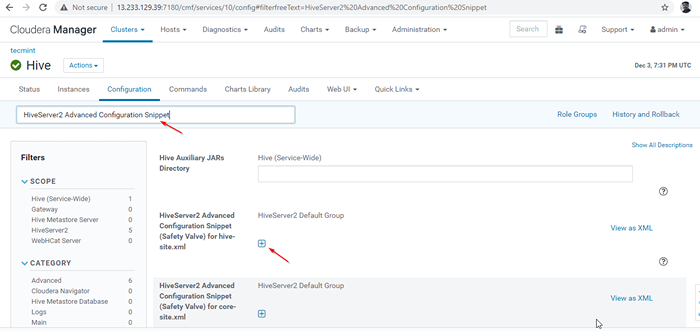 HiveServer2 Advanced Configuration Snippet
HiveServer2 Advanced Configuration Snippet 25. Sobald die Eigenschaft eingegeben wurde, klicken Sie auf 'Änderungen speichern''.
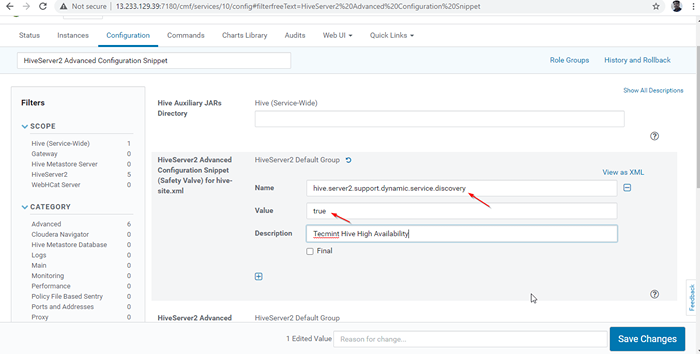 Eigenschaft hinzufügen
Eigenschaft hinzufügen 26. Wenn wir Änderungen an der Konfiguration vorgenommen haben, müssen die betroffenen Dienste neu gestartet werden, indem Sie auf das orangefarbene Farbsymbol klicken, um die Dienste neu zu starten.
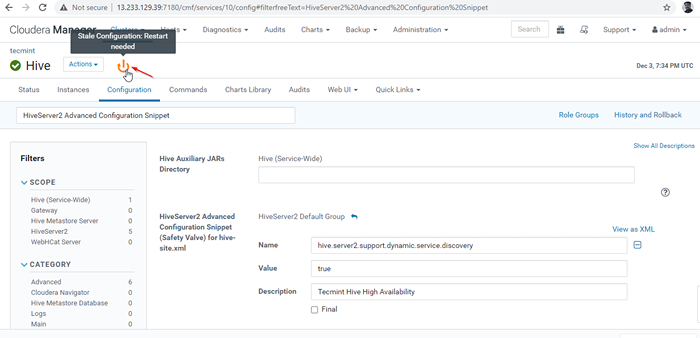 Dienste neu starten
Dienste neu starten 27. Klicken 'Stale neu starten' Dienstleistungen.
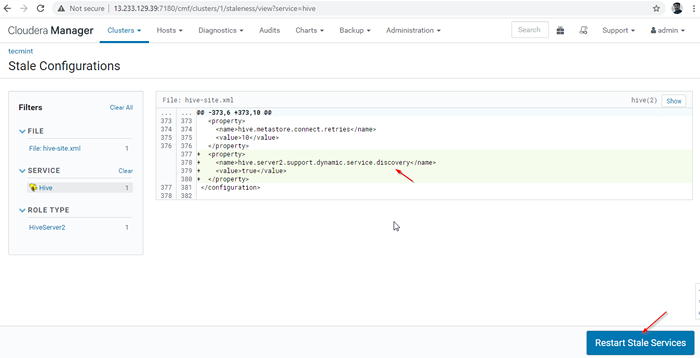 Stalendienste neu starten
Stalendienste neu starten 28. Es stehen zwei Optionen zur Verfügung. Wenn sich der Cluster in der Live -Produktion befindet, müssen wir den Rolling -Neustart bevorzugen, um den Ausfall zu minimieren. Während wir neu installieren, können wir die zweite Option auswählen. 'Die Client-Konfiguration neu einsetzen', und klicken'Jetzt neustarten''.
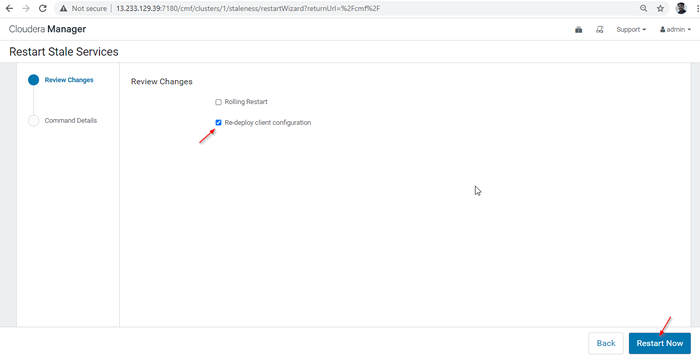 Die Client-Konfiguration neu einsetzen
Die Client-Konfiguration neu einsetzen 29. Sobald der Neustart erfolgreich abgeschlossen ist, erhalten Sie den Status. 'Fertig''. Klicken 'Beenden'Um den Prozess abzuschließen.
 Beenden Sie den Prozess
Beenden Sie den Prozess 30. Jetzt werden wir die verbinden Hiveserver2 Verwendung Zookeeper Entdeckung Modus. Im JDBC Verbindung, die Zeichenfolge, die wir verwenden müssen Zookeeper Server mit seiner Portnummer 2081. Sammeln Sie die Zookeeper -Server, indem Sie zu gehen Cloudera Manager -> Zookeeper -> Instanzen -> (Beachten Sie die Servernamen).
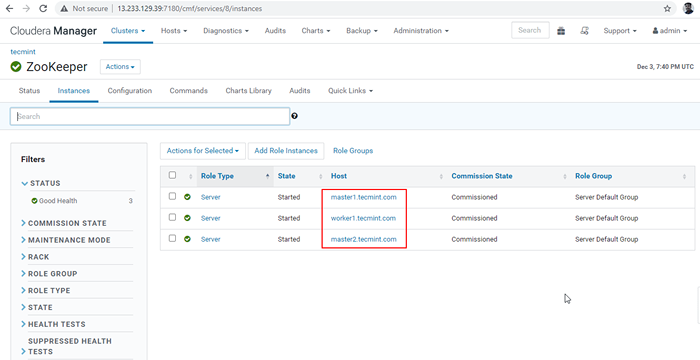 Zookeeper -Server
Zookeeper -Server Dies sind die drei Server mit Zookeeper, 2181 ist die Portnummer.
Master1.Tecmint.com: 2181 Master2.Tecmint.com: 2181 Worker1.Tecmint.com: 2181
31. Jetzt komm in linke.
[[E -Mail geschützt] ~] $ Beeline
 Schließen Sie eine Verbindung zu Beeline an
Schließen Sie eine Verbindung zu Beeline an 32. Geben Sie die JDBC Verbindungszeichenfolge wie unten erwähnt. Wir müssen die erwähnen Service Discovery -Modus Und Zookeeper Namespace. ''Hiveserver2'ist der Standard -Namespace von HiveServer2.
Vorhöhe>!Verbinden Sie "JDBC: HIVE2: // Master1.Tecmint.com: 2181, Master2.Tecmint.com: 2181, Worker1.Tecmint.com: 2181/; ServicediscoveryMode = Zookeeper; ZookeepernamePace = HiveServer2 "
 Geben Sie die JDBC -Verbindungszeichenfolge ein
Geben Sie die JDBC -Verbindungszeichenfolge ein 33. Jetzt ist die Sitzung mit verbunden Hiveserver2 Laufen Master1. Führen Sie eine Beispielanfrage aus, um zu validieren. Verwenden Sie den folgenden Befehl, um eine Datenbank zu erstellen.
0: JDBC: HIVE2: // Master1.Tecmint.com: 2181, mast> Datenbank tecmint erstellen;
 Datenbank erstellen
Datenbank erstellen 34. Verwenden Sie den folgenden Befehl, um die Datenbank aufzulisten.
0: JDBC: HIVE2: // Master1.Tecmint.com: 2181, mast> Datenbanken anzeigen;
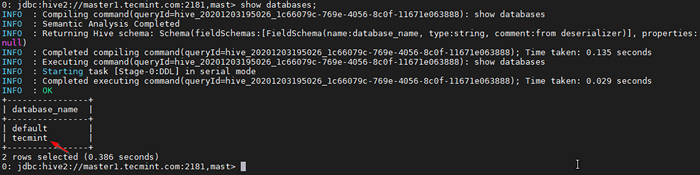 Listendatenbank
Listendatenbank 35. Jetzt werden wir die hohe Verfügbarkeit in validieren Zookeeper -Erkennungsmodus. Gehe zu Cloudera Manager und stoppen die Hiveserver2 An Master1 Das haben wir oben getestet.
Cloudera Manager -> Bienenstock -> Instanzen -> (auswählen Hiveserver2 An Master1) -> Aktion für ausgewählte -> Stoppen.
 Wählen Sie Hive -Server
Wählen Sie Hive -Server 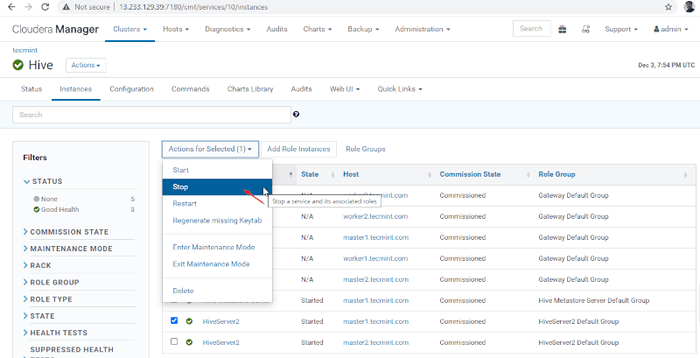 Hive Server stoppen
Hive Server stoppen 36. Drücke den 'Stoppen''. Sobald Sie gestoppt sind, erhalten Sie den Status. 'Fertig''. Überprüfen Sie die Hiveserver2 An Master1 durch Navigieren in Bienenstock -> Instanzen.
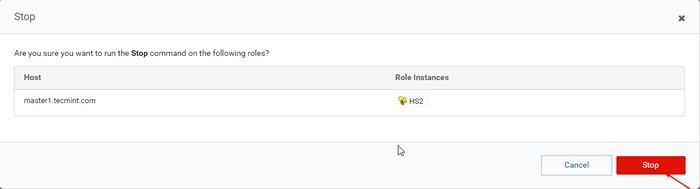 Hive Server stoppen
Hive Server stoppen 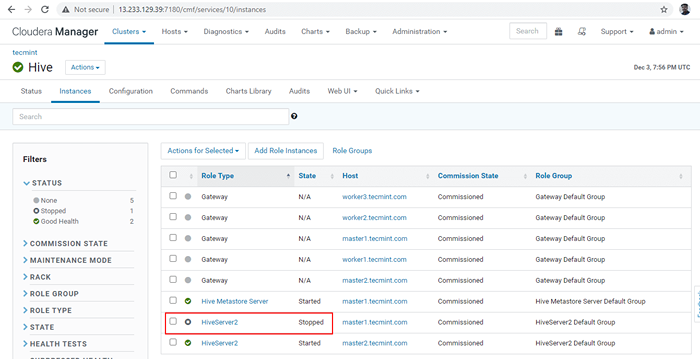 Überprüfen Sie den Hive -Server
Überprüfen Sie den Hive -Server 37. In die linke und verbinden Sie die Hiveserver2 mit demselben verwenden JDBC Verbindungszeichenfolge mit Zookeeper -Erkennungsmodus wie wir es in den obigen Schritten getan haben.
[[E -Mail geschützt] ~] $ Beeline Beeline>!Verbinden Sie "JDBC: HIVE2: // Master1.Tecmint.com: 2181, Master2.Tecmint.com: 2181, Worker1.Tecmint.com: 2181/; ServicediscoveryMode = Zookeeper; ZookeepernamePace = HiveServer2 "
 Verbinden Sie den Nahlerver2
Verbinden Sie den Nahlerver2 Jetzt werden Sie miteinander verbunden sein mit Hiveserver2 Laufen Master2.
38. Validieren Sie mit einer Beispielabfrage.
0: JDBC: HIVE2: // Master1.Tecmint.com: 2181, mast> Datenbanken anzeigen;
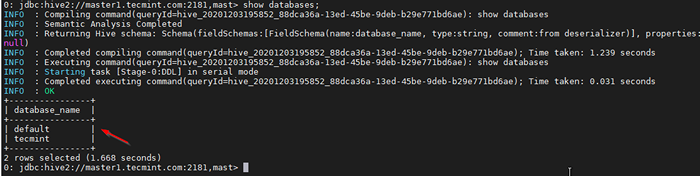 Validieren Sie die Probenabfrage
Validieren Sie die Probenabfrage Abschluss
In diesem Artikel haben wir die detaillierten Schritte durchlaufen, um die zu haben Hive Data Warehouse Modell in unserem Cluster mit Hohe Verfügbarkeit. In einer Echtzeit-Produktionsumgebung mehr als drei Hiveserver2 wird mit platziert Zookeeper -Erkennungsmodus ermöglicht.
Hier, alle die Hiveserver2s registrieren sich mit Zookeeper unter einem gemeinsamen Namespace. Zookeeper dynamisch entdeckt die verfügbaren Hiveserver2 und legt die Bive -Sitzung fest.
- « So installieren Sie VMware Workstation 16 Pro unter Linux -Systemen
- So installieren Sie einen Kubernetes -Cluster auf CentOS 8 »